
“Oh, Pheebs is short for Phoebe I thought that’s just what we called each other.”
You are watching Friends on Netflix and your sister asks you if the net is down. You see that your Netflix hasn’t stopped, and the video is playing smoothly, so you say no. Your eyes then catch the wifi symbol, the net is down. How is this possible? All thanks to caching in javascript.
Table of Contents
What is caching?
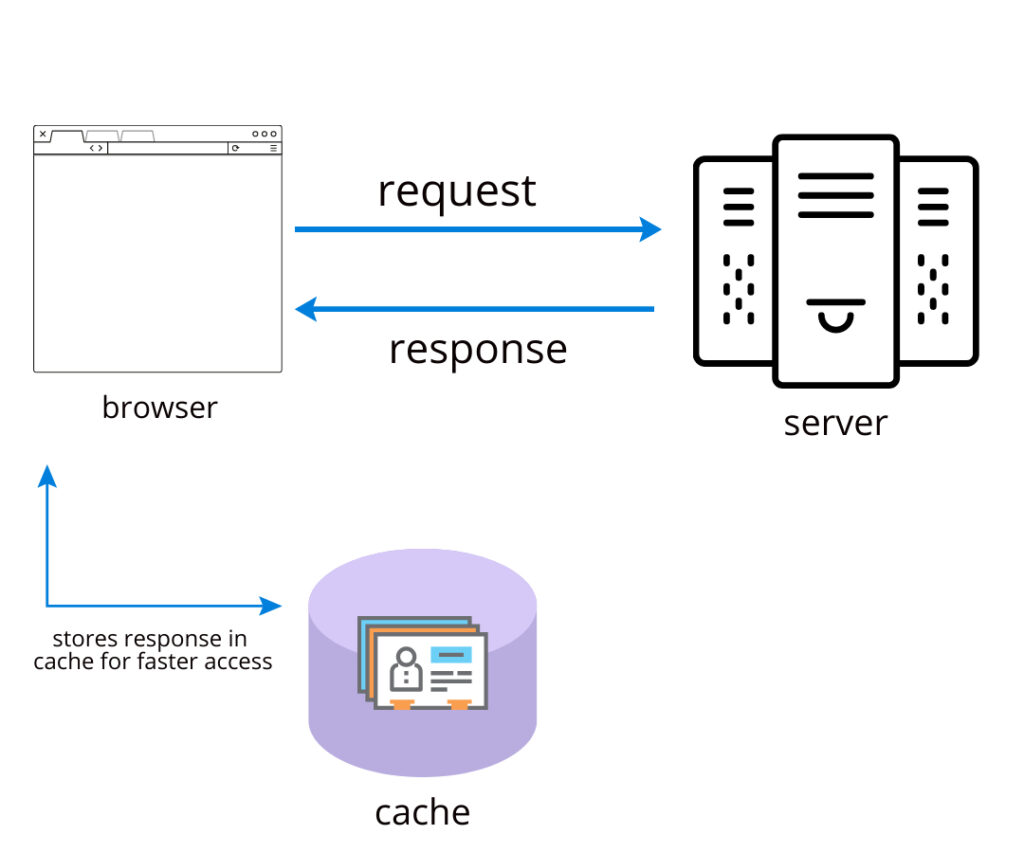
Caching is the process of storing data. Browsers implement this to reduce the time and resources that a page needs to load. This in turn makes our applications faster and improves user experience. Browsers provide a mechanism to store responses to requests in databases so that when the user comes back to the site or is experiencing flaky connections, we can retrieve responses from this database instead of making another request.
Join our discord server for more such content on tech
How Does the Browser Know What to Cache?
So the question arises, how does the browser know what to cache. Here’s where cache policy comes in. A cache policy is a set of rules that determine what the application can cache and for how long. This is done by the use of response headers. Also, learn more about how a browser works internally here.
Let’s go through them
1. Cache-control
2. Etag
3. expires
4. pragma
Cache-control
Cache-control is an HTTP header that defines catching policies that are used to control caching in browsers. These policies include where a resource is cached, its expiration and how it’s cached.
For eg
cache-control: no-cache, no-store, max-age=120, must-revalidate
no-cache
It tells the browser not to use the cache immediately, but to make a validation request to the server to check if the cache is fresh. This validation is done using the Etag header. It is mostly used for HTML files because obviously, the files change and it makes sense to check them.
no-store
As the name suggests, it tells the browser not to store any content. This is used to deal with sensitive data or data that changes too often.
max-age
max-age indicates the time in seconds the resource should be cached before it needs to be validated. For eg max-age=120 means that the resource should be cached for 2 minutes. RFC 2616 suggests that the max-age should not be more than a year.
On the contrary, expires header contains an absolute date when to consider the cache stale.
public
This indicates that the resource needs to be stored in a shared cache and can be cached by any cache.
private
Opposite of public, private directive causes the browser to store responses in a private cache. This usually refers to user-personalized content like session information, tokens etc.
s-maxage
This is similar to the max-age header but we use it for shared caches.
must-revalidate
This forces the browser to validate the cache before reuse. It is used with max-age. Now, you must think this is the same as no-cache. But HTTP allows cache reuse, once the server is disconnected. This header is used to prevent this behavior.
proxy-revalidate
This is the same as must-revalidate but applies to shared cache.
no-transform
tells the browser not to transform the resource content. Some intermediaries transform content like compressing an image. This directive instructs against it.
Etag
This is usually a hash of response contents. This is primarily used by the browser to check if the cache copy it has is stale or not. Every time a resource changes, a new Etag is generated. So the browser can use this Etag to query the server to determine if the cache is stale. This saves bandwidth as the server doesn’t need to send the entire response if Etag hasn’t changed.
ETag: "23a36df451435fcc85e4d41a142743d9e25f39d4" ETag: W/"2013"
Expires
This header provides an expiration date, after which the cache will be considered stale. For eg
Expires: Sat, 24 Sept 2022 21:00:00 GMT
Pragma
It is an outdated HTTP/1.0 header that provides backward compatibility. Pragma: no-cache is the same as Cache-control: no-cache.
Cache API in javascript
Cache API was created for service workers to have more control over caching resources in javascript. Resources include API responses, assets, images, etc. With this, service workers can cache resources and use them later or when offline.
Steps in working with cache API
1. Detecting if the browser supports cache API
2. Create/initialize the cache API
3. Add/update items to cache
4. Retrieve items from the cache
5. Delete items in the cache
1. Detecting if the browser supports cache API
The cache API is not present in older browsers but is in all modern ones. Therefore it is necessary to check first if the browser supports cache API. Following browsers support cache API –
- Edge >= 17
- Opera >= 27
- Safari >= 11.1
- Firefox >= 39
- Chrome >= 40
- iOS Safari => 11.4
- UC Browser >= 11.8
- Chrome for Android >= 67
For this, we check if the cache object is present in the window
caches is an instance of CacheStorage.
2. Create/Initialize cache API
open method is used to create a new cache. This returns us a promise which resolves after the cache is created. This method first checks if the cache already exists, if it doesn’t then it creates a new cache.
This cache can only be accessed by your origin ie it is linked to the current domain. You can also create multiple caches for the same domain and access them by caches.keys().
3. Add/update items to cache
There are 3 methods for adding items to a cache
1. add
2. addAll
3. put
1. add()
add takes a single parameter which can either be a URL or a request object. It automatically fetches the resources and adds in the cache for us. If the fetch fails, it returns an error response and nothing gets cached.
2. addAll()
addAll() takes an array of URLs or request objects, fetches them and caches it. It returns a promise when all the objects are cached. If one or more requests fail then the items are not cached.
3. put()
put method takes in two parameters, key and value. Here, we need to fetch the resource first and add it to the cache. If the value pre-exists, put() will override it with the new value.
4. Retrieve items from the cache
match()
match method is used to fetch items from the cache and returns a promise when the request is found. It takes in two arguments, first one can be a URL string or a request object. If the argument is a URL it is converted into a request object. The second argument is options that has key/value pairs that tells match what factors to ignore while matching requests.
There are different factors that the browser uses to check if the two requests are the same. For eg – two requests can have the same URL but can have different methods (POST, GET, PUT etc).
response is a response object that looks like this.
Response {
body: (…),
bodyUsed: false,
headers: Headers,
ok: true,
status: 200,
statusText: “OK”,
type: “basic”,
url: “website.com/resource”
}
5. Delete items in cache
delete()
This method takes in the URL or the request object and deletes the entry from the cache.
You can also delete the entire cache by using the delete method on the caches property.
Final thoughts
In this article, we got the hang of the CRUD operations that cache API provides us for caching in javascript. I hope you learned something new and valuable through this post. Stay tuned for the next part where we’ll talk about service workers and PWAs (progressive web apps).
You’re so interesting! I don’t think I’ve read through something like
this before. So nice to find someone with some genuine thoughts on this subject.
Seriously.. thanks for starting this up. This web site is something that is needed on the internet,
someone with a little originality!
I think the admin of this web site is truly working hard in favor of his website,
as here every stuff is quality based material.
wonderful publish, very informative. I wonder why the other specialists of this sector don’t realize this. You should continue your writing. I am confident, you have a great readers’ base already