Your palm lines tell a lot about you…
but your Browser history tells everything.
Browsers are an important piece of software that we use in our everyday lives. It allows us to surf the internet by downloading web pages and rendering them in a way understandable by humans. You might have heard some of the popular names such as Chrome, Firefox, Safari, Opera, etc. But have you ever wondered how this software parses these web pages written in HTML, CSS, and JS? how the browser works internally?
Browser’s internal functionality is an important piece of knowledge for web developers. Browser is millions of lines of structured, complicated code written in C, C++. Before we dive into the internal functionality, let’s first understand the components in a browser.
Join our discord server for more such content
Table of Contents
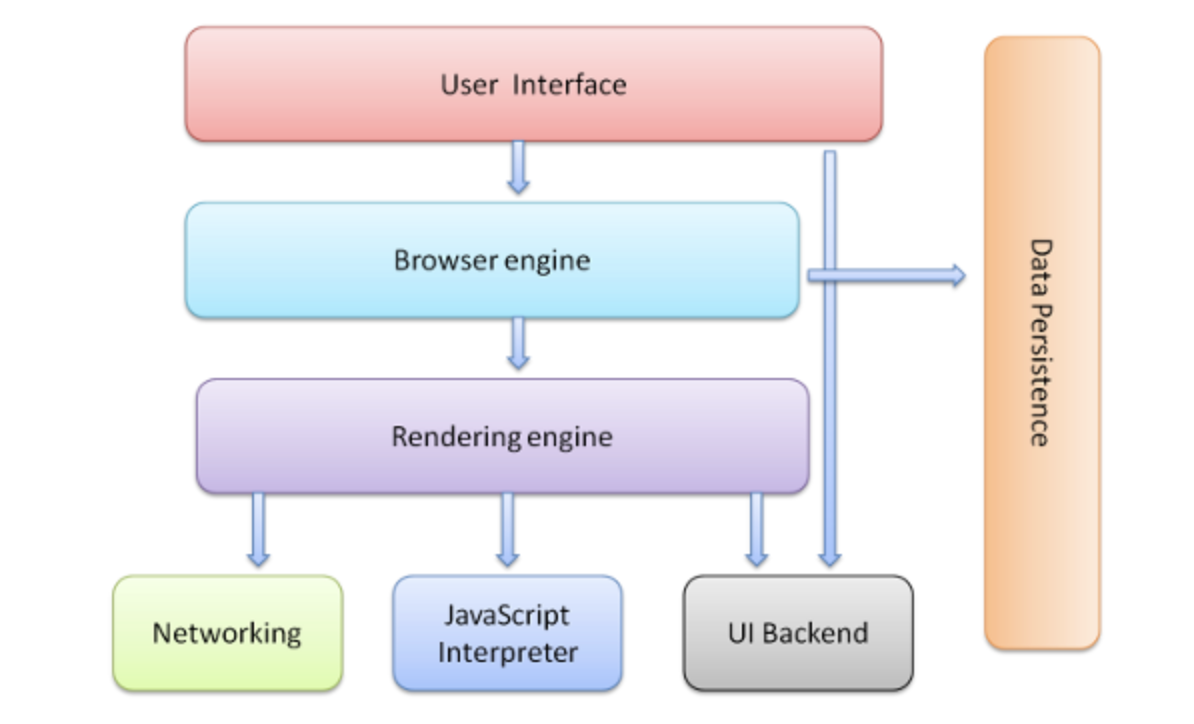
Components of a browser
- User Interface
- Browser engine
- Rendering engine
- Networking
- Javascript interpreter
- UI Backend
- Data Persistence
1. User Interface
The user interface is the top bar, where the user interacts with the browser. It includes the address bar, back, and next buttons, refresh, home button, bookmark option, etc. Every other part except the window where you can see the requested page comes under this part
2. Browser engine
The browser engine acts as an intermediary between the UI and the rendering engine. It gets inputs from the UI and uses them to handle the rendering engine to create an interactive visual representation(DOM)
3. Rendering engine
This is the most important component. It parses HTML and CSS and displays them. It interprets HTML, XML documents and images that are styles using CSS. HTML parsing creates DOM and CSS parsing creates CSSOM. An important point to note here is that this does not happen in parallel. For eg – HTML parsing stops when CSS parsing is in process. Both of them combine to form a render tree.
Every browser has its own rendering engine. Some of them are listed below
- Internet Explorer: Trident
- Firefox & other Mozilla browsers: Gecko
- Chrome & Opera 15+: Blink
- Chrome (iPhone) & Safari: Webkit
4. Networking
Its main job is to fetch resources using common internet protocols HTTP or FTP. It also implements a cache to store the fetched documents to reduce network traffic. It additionally takes care of the security issues related to web communication.
5. Javascript interpreter
As the name suggests, it parses and executes javascript code. It then hands over the result to the rendering engine. If the script is an external file, it is first fetched and the parser is kept on hold until then
The application of the JS engine isn’t restricted to browsers. For eg – Chrome’s V8 engine is an important component in node and deno systems.
Some Javascript interpreters that different browsers use are as follows –
- Google Chrome: V8
- Mozilla Firefox: SpiderMonkey
- Opera: V8
- Safari: Nitro
- IE: Chakra
- Edge: Chakra
6. UI Backend
It is used for drawing widgets like windows, combo boxes, etc. It uses the underlying operating system’s user interface methods.
7. Data Persistence/ Storage
We all know that browsers store data such as cookies, cache, bookmarks etc by supporting storage mechanisms such as localStorage, IndexedDB, WebSQL, and FileSystem. It creates a small database on our local system where it stores all these details.
Rendering Engine

The networking engine sends documents to the rendering engine in chunks of 8KBs.
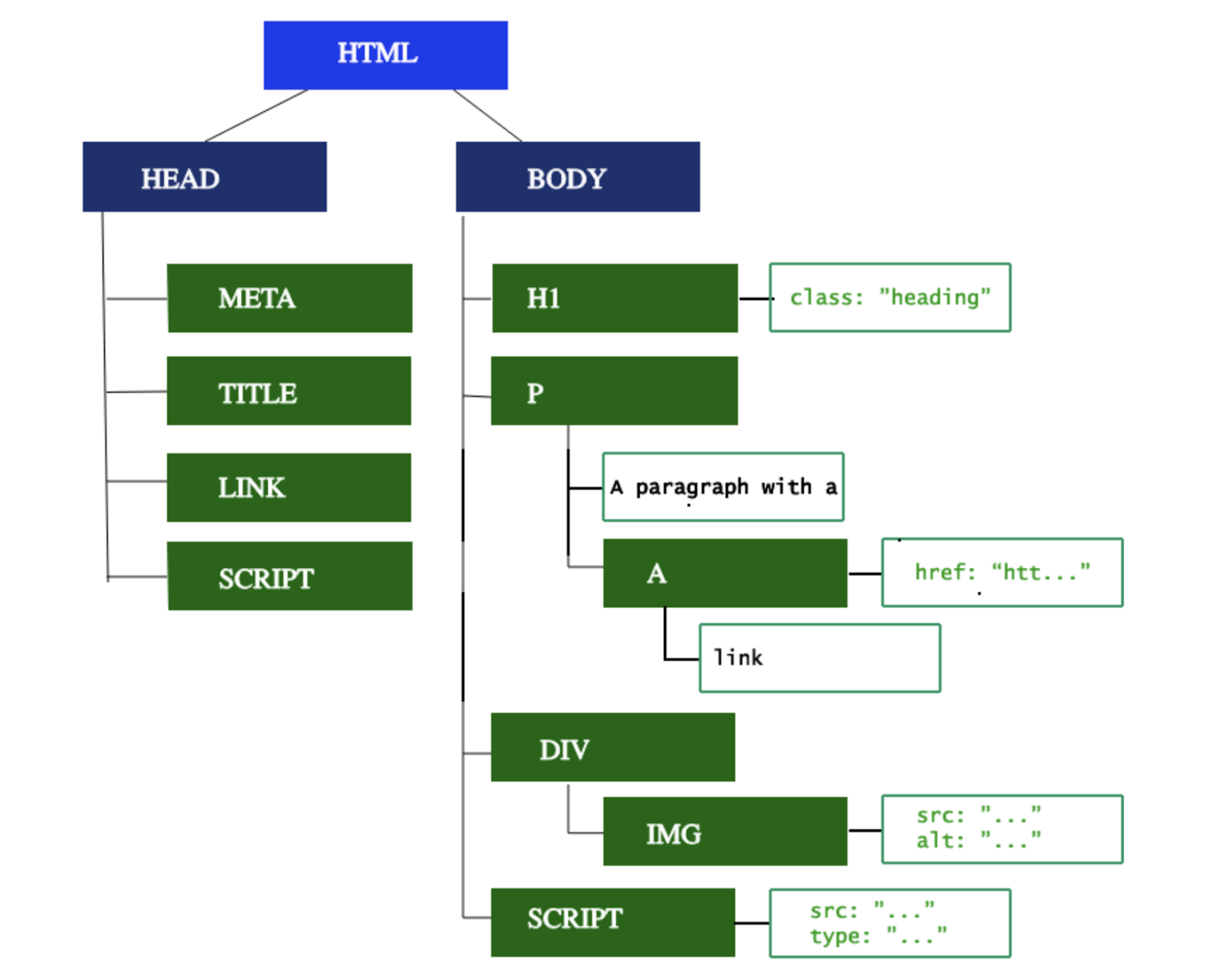
Building Dom
This cannot be defined by context-free grammar but is defined by Document type definition. DOM creation does not use top-down or bottom-up parsers, instead, browsers have custom parsers defined by HTML5 specification.
Building DOM involves two steps: tokenization and tree construction.
Tokenization – HTML document consists of start and end tags. Tokenization is parsing this input to tokens
Tree construction – Here the tokens generated in the previous step are converted into a tree. The root of the tree is the HTML tag. This tree represents the relationship and hierarchies between elements. Each token has a DOM element relevant to it. This element is added to the DOM tree and also a stack. The stack is used to check nesting mistakes and unclosed tags
Building CSSOM
Unlike HTML, CSS parsing can be done by top-down or bottom-up parsers
CSS parsing is render-blocking. If it was not render blocking our pages would look something like this
CSS parsing is done in a similar way, bytes converted to characters then to tokens and finally a tree. The browser starts with the most general rule and then recursively processes the computed styles by traversing the nodes of the CSSOM.
Scripts
Script parsing halts document parsing. Here first the browser fetches the script from the network, executes it and then continues parsing. The reason for this is that scripts can change something major in HTML/CSS. So why would we parse the document first and then allow scripts to change them again? Doesn’t make sense right.
We can use async or defer attributes to avoid this. Defer attribute to a script does not halt parsing and executes after the parsing is done. Scripts with async attribute load in the background and run when ready.
DOM+CSSOM = Render tree
Dom and CSSOM combine to form a render tree. This tree is a visual representation of how the elements would be displayed.
Firefox calls elements in a render tree as frames and WebKit calls them renderer or render obj. These elements know how to layout and paint themselves and it’s children.
All elements from the dom tree are not added to the render tree. One example is the head tag. Also, elements with display value as none are not added to this tree, on the other hand, elements with visibility hidden will appear in the tree. So now you know the difference between these two.
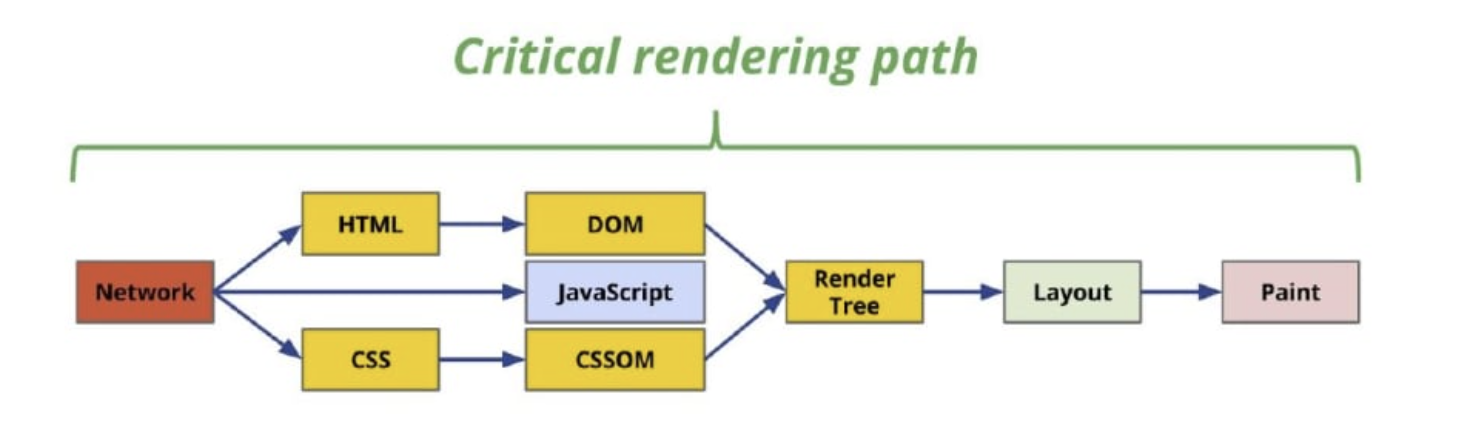
Critical Rendering Path
Critical rendering path is the path that the browser follows to convert HTML, CSS and Javascript to pixels on the screen. Optimizing CRP improves the time to first render. We won’t go into details about this topic. CRP can be optimized by making our critical assets as small as possible by minifying or compressing them, prioritizing which resource gets loaded and the order in which they are loaded.
Layout
Here the height, width and position of the elements are determined. It is a recursive process. It starts from the root element i.e. the HTML element and continues recursively calculating geometric information of renderers that require it.
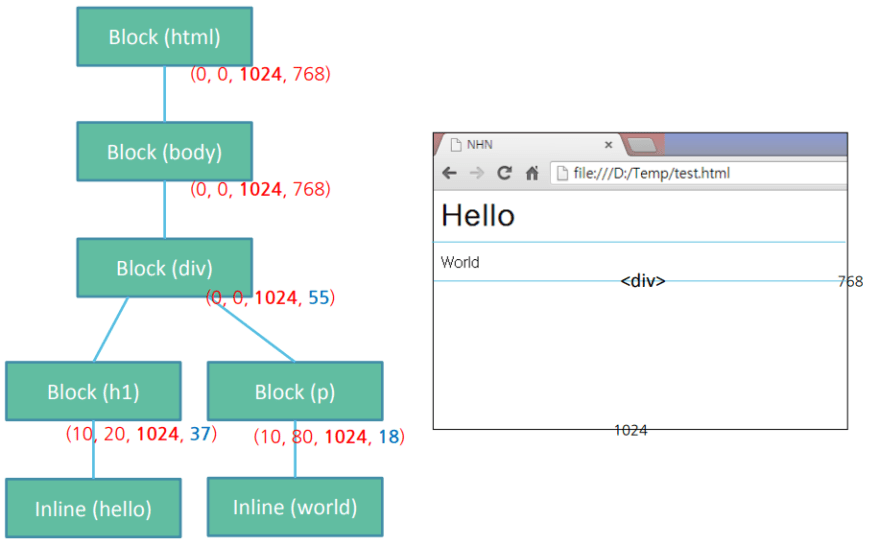
The first time size and position of the nodes are determined is called layout. Subsequent recalculations of node size and locations are called reflows.
Dirty bit
To avoid recalculation of all the nodes, renderers use a “dirty bit system”. Whenever a renderer is changed or added, it marks itself and its children dirty.
There are two flags
Dirty – node is dirty
Children are dirty – at least one child is dirty
Layout algorithm
- Parent determines its width
- For each child, parent
- determine their position(by setting their horizontal and vertical coordinates)
- Call their layout method if they have a dirty descendant
- Parent calculates its own height using children’s accumulative height, margin and padding
- Set’s its dirty bit to false
Painting
This is the last stage of rendering. Here the paint() method is called to convert the output of the layout phase to pixels. The browser needs to do this quickly.
The painting order (from back to front) is:
- Background Color
- Background Image
- Border
- Children Render Objects
- Outline
Final thoughts on how a browser works internally
After all these stages you can now see and browse the page. 🙂
Now you know how a browser works internally, please leave a comment below if you think I’ve missed something. Also, do read our article on js polyfills here. Thanks and happy coding 🙂
Spot on with this write-up, I really feel this web site
needs a lot more attention. I’ll probably be
returning to read through more, thanks for the info!